今天没吃药 感觉自己萌萌哒~~
如何正确的入门Vulkan?
如何正确的入门Vulkan?
原作者:wicast C
作者:wicast C
链接:https://www.zhihu.com/question/424430509/answer/1632072443
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
个人最近一直在捣腾Vulkan相关的内容,来说说我的路径和心得
看题主说有基础知识那就假设你学过OpenGL,我自己OpenGL的水平其实就只到扫过learnopengl,godot里玩过简单的shader,learnopengl 里的样例代码能看懂这样。只要理解里面的思路方法就ok,有这些就足够学vk了。至于怎么学图形学原理,玩shader其实算是另一个垂直领域的知识,你用不用vk其实没太大关联了,我们这里就只关注vulkan本身是如何操作 gpu 的。
Introduction - Vulkan Tutorialvulkan-tutorial.com
一个月的话相信你应该走完这个教程了,对vk有个初步的认知了,但你可能像我当初一样看着这堆代码还没法建立一个体系的认知。反正初学者走完这篇完全不能算入门,vk有太多细节需要学习
vulkan 可以说接口繁杂,对象众多。
要理解 vulkan 我觉得最重要的是,得先理清vulkan的那些对象的作用以及各自的关联性。本身这些对象距离实际使用的上层概念有一定距离,而各自关系又是比较复杂,只有吃透这一部分才能顺畅地去使用。
在amd那边有张叫 understanding vulkan objects
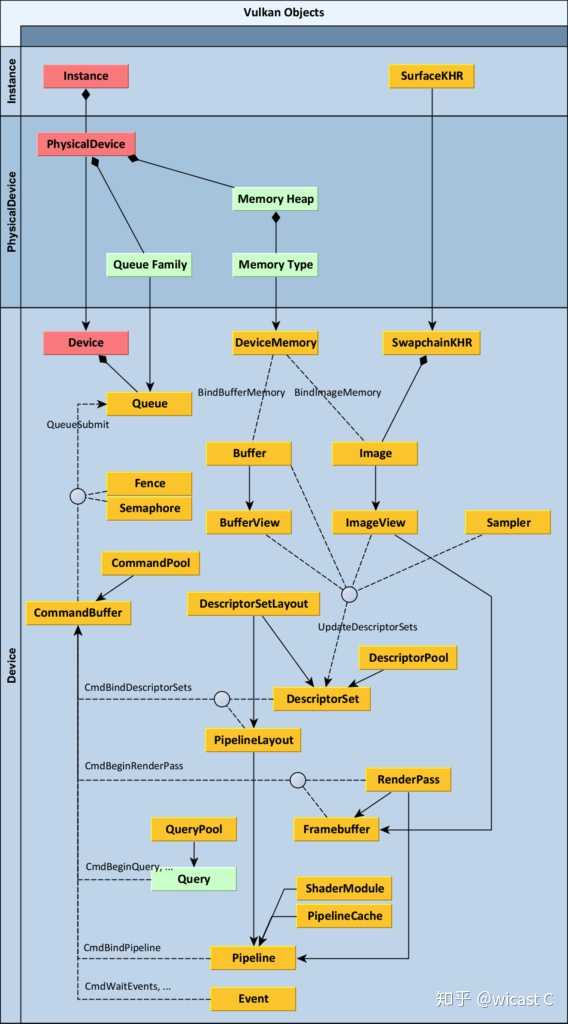
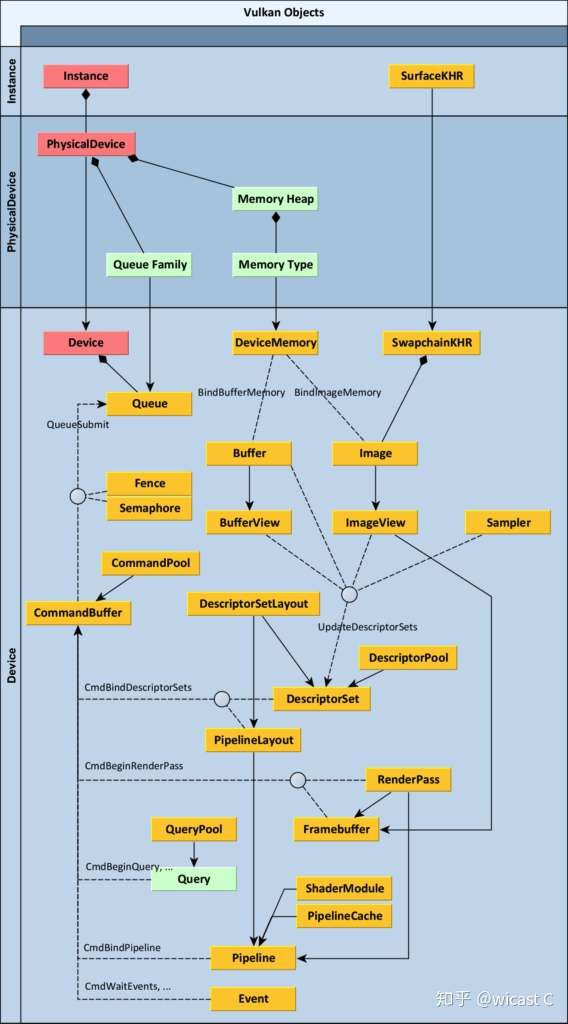 已经准确揭示了各种对象的关系了
已经准确揭示了各种对象的关系了
但对于实际使用光看这个图可能还是晕,所以我们从功能这个维度进行一个大致的划分,以下是我自己整理的关系图:
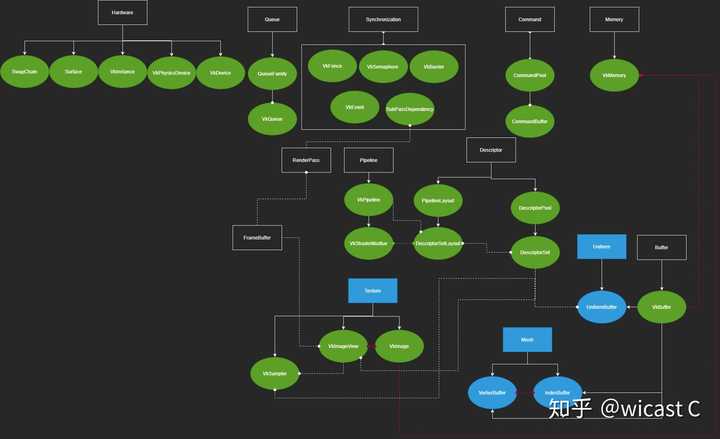
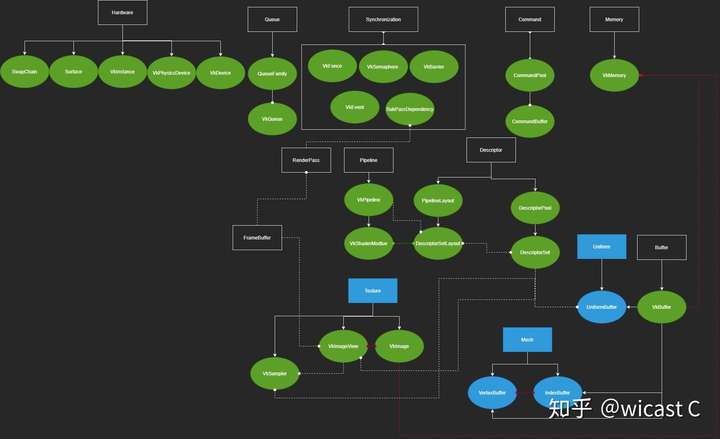 黑方框为vulkan的基础对象,蓝方框为我们为方便抽象的对象;实线可理解为直接派生,虚线为依赖;红线为强关联,DescriptorSet和Shader的绿线表示他们只有逻辑上的联系
黑方框为vulkan的基础对象,蓝方框为我们为方便抽象的对象;实线可理解为直接派生,虚线为依赖;红线为强关联,DescriptorSet和Shader的绿线表示他们只有逻辑上的联系
解释一下各个对象,TLDR,你觉得自己都懂的话就可以跳过这段。
Hardware:即为硬件直接给出的几个组件,这5个都很好理解不多赘述,而其中 VkDevice 这个几乎和后面所有对象都关联所以不画连线了
在说 Queue 和 Command 前,这里就要先说到 Mantle 世代 api (都是从Mantle 演变而来我们就叫他们 Mantle 世代好了)对于上世代 api 的第一大区别了:这一代的api将图形绘制命令分成了 Record 和 Submit,vulkan 中对应了 command buffer 和 queue,凡是vkCmd开头的调用都是录制命令,vkQueue 开头的都是提交(vkQueuePresentKHR 可以理解为特殊的提交)。
Queue:队列这个东西是从 Mantle 世代的api出现的,我个人的理解是对硬件执行流水线的抽象,通过提交任务执行图形计算,简单理解的话就是提交的内容对应某一个 queue 上只能依顺序执行(gpu 的并行其实并不是像很多人想的像多线程那样fire多少个 task 他就自动并行,就vulkan来讲提交的任务在一个 queue 上是按一定规则排列的)。
- QueueFamily与Queue:翻译过来应该叫做队列家族,每个Family里会有若干queue,常见的 Family 为三种:Graphic,Compute和 Transfer。Graphic一般是全能的啥都能做,内含的queue数量也是最多;Compute不支持Graphic相关功能;Transfer可以专门用于上传数据。这种分法不是绝对的,要看具体硬件提供的queueFamily数量和支持的功能。vulkan 里的对单个queue 是禁止同一时间有多个线程进行操作的,所以申请多个 queue 能做到多个线程做submit。
Command:录制使用的对象是command pool和command buffer,为啥这么设计现在可以先不管。录制本质上就是一个类似 push_back 的工作,每次调 vkCmd 就往 command buffer 塞内容进去,至于这个 command buffer 在cpu还是gpu这个完全取决于硬件和驱动实现,对vk程序员是透明的。录制结束之后就可以提交给queue执行了,所以理论上是这个时候gpu才开始真正执行。分成录制和提交的原因就是为了多线程。在vk里大家说的多线程渲染其实基本可以理解为多线程录制,多线程提交其实不太常见,也不好写,而且有更好的方案(往command buffer录制并不是直接就能多线程操作的,有很多限制,vk里有一个叫 secondary command buffer的东西可以直接用于多线程录制,不需要任何额外同步)。
这里有一篇arm关于多线程渲染流程最简单的描述
Multi-Threading in Vulkancommunity.arm.com
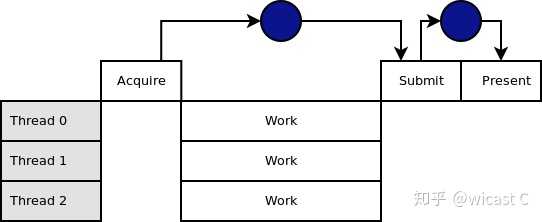
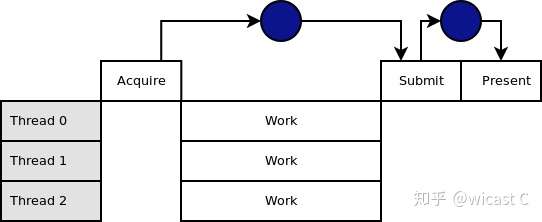 无优化的多线程渲染,work就是我所说的record
无优化的多线程渲染,work就是我所说的record
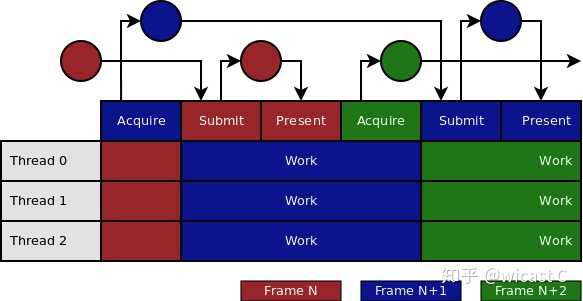
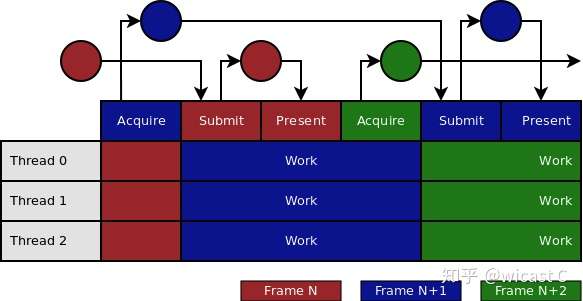 比起上一种做了overlapping,吞吐量上去了,最理想的实现应该就是这种了
比起上一种做了overlapping,吞吐量上去了,最理想的实现应该就是这种了
Buffer:Vulkan主要有两种 Buffer 和 Image,Buffer一般用于vertex、index以及uniform,Image用于位图数据,也就是贴图。而Buffer要真正使用起来还得配备一个 VkDeviceMemory,下面会说。
- Mesh:这个比较好理解,vertex、index各自对应一个buffer对象和一个memory对象组成一个Mesh,tutorial里也算写的很清楚。
- Texture:VkImage 除了 VkDeviceMemory 还需要 VkImageView 和 VkImageSampler,VkImageView 相当于一个 accessor,具体操作都需要操作这个accessor,所以基本上VkImage和VkImageView就是个强绑定关系。VkImageSampler是采样器,anisotropy、mips等在这里设置,可以多个图共享一个采样器。
- Uniform:类似Mesh,只不过这个Buffer对应的结构体一定一定要注意内存对齐的问题!!!不同编译器不同平台编出来的内存对齐模式都可能不一样,而vulkan对传过来的数据是有对齐要求的,这个问题我吃过药,tutorial那一章最后写过,当时给我跳过去了,结果shader里拿到的数据怎么都不对,更要命的是这个问题是validation layer无法检查出来的!
Memory:这里就是第二大不同了,以前的 OpenGL 创建一个Texture就能直接上传数据直接用了,uniform都是api直接传输的。到了vulkan里gpu的内存也放给程序员来管理了,VkDeviceMemory 这个对象就是代表你分配的显存。这和 c/c++自己手写内存分配器是差不多一个意思了,你可以定制很多更高级的分配策略,而且vulkan非常不鼓励小分配,vulkan的分配次数每个设备都是有上限的,就是为了让你做 suballocation。而这个活有现成的 vulkan memory allocator可以拿来直接用。
Synchronization:
- vulkan不光让你自己管理内存,同步也需要手工做,cpu提交之后如何知道gpu完成任务了呢,所以有fence充当cpu和gpu之间的同步工具,cpu通过等待fence知道gpu完成任务。
- Semaphores 用于两个提交直接建立依赖,submit和present这两个提交如果没有semaphores,用fence监听submit再通知submit肯定是低效的,所以两次submit之间通过semaphores直接在gpu内部建立依赖。
- barrier是做啥的呢,vulkan上传上去的数据相当于都有一个状态(usage,access mask,VkImageLayout等),这个状态首先可以给gpu提供更多的优化信息,其次在操作数据时由于gpu直接操作的数据是先在一个缓存里,在另一个阶段读取这个数据的时候可能不是同一套核心的寄存器,这时候就会发生缓存不一致的问题,所以插入一个barrier就能告诉gpu这段写完下个阶段你得先同步缓存。
- event不太常用,我自己也没用过,但功能更精细化属于进阶内容,有兴趣可自行了解。
- subpass dependency这个其实也提供了barrier类似的功能,是 subpass 专用的功能,subpass 算是 vulkan 特有的功能,renderpass 必须包含至少一个 subpass,当它只有一个的时候,dependency 建议留空,vk会补上默认值,自己写其实容易写错,tutorial 里其实就写的有问题。
Pipeline:VkPipeline 定义的是管线状态,隐藏面剔除啊,混合啊都是在这里设置的,而这里最重要的一个状态就是shader是在这里进行绑定的。一旦pipeline创建好了就不能改了,你要换shader就得换个新的pipeline。而 Compute Shader需要再独立的一个 Compute Pipeline,类型一样VkPipeline,但创建方法不同。提一嘴pipeline cache,这个东西就是用来加速shader加载的,因为shader即使是spirv这样底层的代码了,执行对应gpu的shader代码还是需要一趟编译变为gpu专用的最优内容为了节约这个编译时间就搞出了pipeline cache。
FrameBuffer:这个差不多就是 OpenGL 里的 attachment 了,只不过 FrameBuffer 通过引用各种 ImageView 打包成一个集合,FrameBuffer 就是一堆 View 的集合。从 SwapChain 获得的Image 再创建 ImageView 放到 FrameBuffer 里,就能给 gpu 用了。
RenderPass:最初学vulkan最让我迷惑的部分就是RenderPass了,扣了很久的文档和代码才理解,vulkan的RenderPass 本质上描述的是一次渲染我需要的绘制的目标是长什么样的。创建RenderPass时参数里填写的pAttachments其实不是真正的attachment,而是attachment的描述,比如第一个attachment是color,第二个是depth,而 RenderPass 通过 FrameBuffer 才能绑定真正的Image(vkRenderPassBeginInfo里绑定),位置一一对应。这里说一下创建时候为啥也得给一个 FrameBuffer,主要是可以限定这个 RenderPass 不要乱来,能在一创建就能保证和某个 FrameBuffer 相容。之后的渲染流程中只要符合 vk 定义的 Render Pass Compatibility 的 FrameBuffer ,这个FrameBuffer 就能拿来绑定。
Descriptor:shader 里读取数据在 vulkan 里除了 vertex 数据(layout(location = n) in 的形式)剩下最常见的就是 uniform 了,要传输uniform就得通过 DescriptorSet 或 PushConstraint。
先说Descriptor:VkDescriptorSet 的作用是引用用于作为 uniform 的 buffer 数据,主要是 VkBuffer 和 VkImage 两种,VkDescriptorSet 类似 command buffer 需要从一个 DescriptorPool 分配出来,然后通过 vkUpdateDescriptorSets() 方法绑定对应的对象。有了一个 VkDescriptorSet 之后也不能直接用,还需要一个 VkDescriptorSetLayout 来规范约束你这里多少个set,每个set里有多少buffer和image。vulkan支持一个shader用多个descriptorSet读取数据(layout(set=m,binding = n ) 形式),VkDescriptorSetLayout 本身只是个 layout,不存储具体的 set,set 需要在渲染时绑定。有了 VkDescriptorSetLayout 还不够,还需要一个VkPipelineLayout ,主要时因为有 PushConstraint,把前面的 VkDescriptorSetLayout 和 PushConstraint 合一块就是 VkPipelineLayout 了。同时注意 VkPipelineLayout 在创建VkPipeline 时也需要给出,也就是说 Pipeline里的 shader 也需要遵守这个 Layout。而PushConstraint 专门用于小数据传输,性能好但容量也小,直接存储在 command buffer 里的,而不是 VkBuffer,所以也不需要每次更新去 map memory然后 memcpy。当然可以不用 PushConstraint (
好了,理清这些对象之后如何调用 vulkan 其实就非常清晰了,建议自己看着amd的图,对着代码和api按自己的理解也整理一遍,不需要和我一样(而且我这图也主要是为自己看的),等你做完就能有一个体系的认知了。而渲染流程撇开多线程,record&submit,同步。本身和 OpenGL 没什么大的区别。
大致描述一下渲染步骤的主体就是以下这几步:
- vkAcquireNextImageKHR —— 从 SwapChains 获取下一个可以绘制到屏幕的Image
- vkResetCommandPool/vkResetCommandBuffer —— 清除上一次录制的 CommandBuffer,可以不清但一般每帧的内容都可能发生变化一般都是要清理的。
- vkBeginCommandBuffer —— 开始录制
- vkCmdBeginRenderPass —— 启用一个RenderPass,这里就连同绑定了一个 FrameBuffer
- vkCmdBindPipeline —— 绑定Pipeline,想要换shader就得在这里做
- vkCmdBindDescriptorSets —— 绑定 DescriptorSets,可以一次绑多个Set,也可以多次绑定多个Set,同时需要给出 PipeLineLayout
- vkCmdBindVertexBuffers&vkCmdBindIndexBuffer —— 没啥好多说的了,绑模型
- vkCmdDrawIndexed —— 最关键的绘制命令,这里可以根据显卡的特性支持情况换更高级的绘制命令比如indirect,相应的数据绑定也需要改。
- vkCmdEndRenderPass —— 结束 RenderPass
- vkEndCommandBuffer —— 结束 CommandBuffer
- vkQueueSubmit —— 提交执行渲染任务
- vkQueuePresentKHR —— 呈现渲染数据,这时候调用可能 vkQueueSubmit 还没执行完,但 Semaphores 会帮我们打点好。
看到这里都明白了的话基本就是入门了,而具体怎么写代码加高级的功能,这里我要给出几个建议和自己踩过的坑。
- 首先上来第一个点,也是我觉得最重要的一个
Validation Layer 一定要学会用!!!
Validation Layer 一定要学会用!!!
Validation Layer 一定要学会用!!!
vulkan 太复杂了,如何写正确是个实实在在的难题,各种状态维护很容易搞错,所以搞了这个 Validation Layer,能帮你快速定位问题。而 vulkan tutorial 里只教了怎么在应用里设置,但Validation Layer是个外部工具,,它还有自己其他的设置细项,文章末尾只说了vk_layer_settings.txt 可以改这些配置,没说怎么配,我手头的n卡具有一定鲁棒性,即使用错了依然是可以运行的,导致我一开始很多错误都没反馈给我。
其实 vulkan sdk 里自带一个 configurator,用这个调就可以启用各种检查了,一般只有打开这个 configurator 的时候才有效,关闭的时候会自动恢复成默认设置。
吐槽下 vulkan tutorial ,其实它里面的内容有些地方拿 Validation Layer 扫是有问题的,最近版本的可能修了,我学的早期版本。
Validation Layer 是实实在在救狗命的工具,很多问题自己看代码解决是几乎不可能的,下断点报错的位置一般都在submit之类的地方。
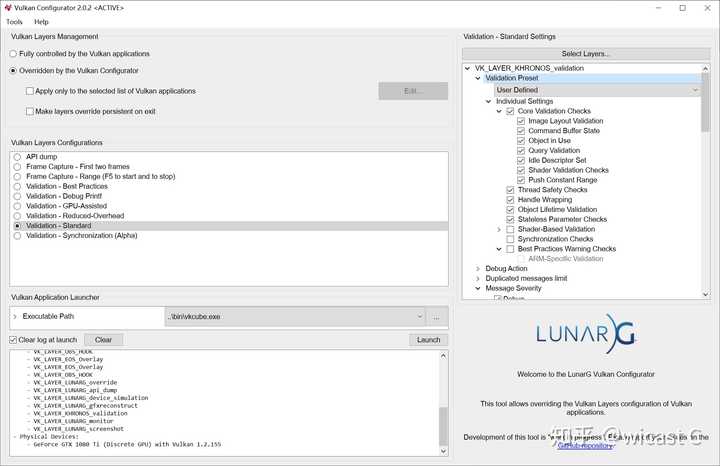
 左边是Layer,右边是具体Layer的配置
左边是Layer,右边是具体Layer的配置
\2. Unifrom buffer 一定记得调整对齐,上面已经提到过,这里写错了 Validation Layer 也救不了你
\3. 多写代码不必我多说了,初学进阶的话现在官方的Sample就非常好有讲解有代码,第二推荐SaschaWillems的Sample,他本人其实就给官方 Sample 写,不过这个repo有些东西还是比较新,比如截至到目前光追更新到了正式版,官方那里还是旧的。
推荐几个我自己觉得不错的repo和读物:
https://github.com/KhronosGroup/Vulkan-Samplesgithub.comhttps://github.com/SaschaWillems/Vulkangithub.com
NVIDIA DesignWorks Samplesgithub.com
这个是nVidia的sample仓库,很多vk开头的都是vulkan的例子
Writing an efficient Vulkan rendererzeux.io
这篇是教的最佳实践,各种对象如何用给出了很多可行方案,值得参考。
2017 DevU - 04 - Syncronizationwww.youtube.com
vulkan同步是个难点,这里可以看看这个演讲帮助理解。
Yet another blog explaining Vulkan synchronizationthemaister.net
同上
\4. RenderDoc 之类的工具玩熟对 debug 是有很大帮助的,这种工具你要行当里混肯定要多玩。我曾经犯过一个很蠢的问题,渲染出来一片黑, Validation Layer 无任何报错。本来想试试RenderDoc debug pixel,结果怎么也不能调试。后来发现改代码的时候物体位置也改了,默认开始相机里就是啥都没有……自然 debug pixel 没用。RenderDoc 有个功能叫 overlay,随便用一个就能直接看出我这画面是真的啥都没画的还是画失败了。
\5. 官方的spec算是一个终极参考,远比市面上的书来的靠谱,书上说的再细致也比不过spec来到可靠,啃书一样是吃力不如直接看spec来的明确。
Khronos Vulkan Registrywww.khronos.org
这里能下到最新的pdf可以离线看,建议就下 all published Extensions 的这个,有关扩展的内容也包含在里面。
\6. 遇到问题实在不能解决的时候,k组的官方论坛是给非常好的提问地点,还是有活人在那里解答问题的,此外reddit的vulkan版也是不错的选择,不过国内的社区我其实就不怎么了解了。英语不好的话只能自己想办法了。
https://community.khronos.org/c/vulkan/24community.khronos.org
以上,希望帮到你(其实我也是顺道留个档总结下)。
2020/12/20:加了arm对多线程渲染的解释,添加了queueFamily 的解释
原作者:MaxwellGeng
作者:MaxwellGeng
链接:https://www.zhihu.com/question/424430509/answer/1635986087
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
闫老师说过:你要学习的是图形学,不是一个API,这一点就很重要。Vulkan是很轻薄很底层的API,这就意味着如果你没有完整的着手开发过一套上层的渲染,就根本不知道怎么去封装效率最高,怎么去封装看起来既简洁又优雅,甚至可能就只能画个三角形就不知道怎么做了。所以我的建议是,先使用一个现有的渲染框架实现一套管线。
我本人学习DirectX 12到完成基础组件的封装大概只用了一个月,其中有绝大多数时间其实是在熟悉DX那堆很“Windows”风格的奇葩调用上,而Vulkan就不会有这样的问题,因为在此之前我已经使用Unity那套比较傻瓜式的API开发一套完整的上层管线了,比较清楚在工程中会遇到哪些可能的方向,所以接下来的底层开发就是有bear来,在简洁性和优雅性上也能够做到一个可以接受的程度。
通过对上层的学习,敲定了封装的形态以后,就要考虑自己这套封装怎么做才能够让性能最大化,毕竟是底层开发,如果说优美和简洁的重要性是第一位,那么性能最大化则永远是排在第0位的(既然题干说在工作,那么我就假设是做工程项目了)。C++讲究zero overhead abstraction,而vulkan就非常能够实现这一点,vulkan在设计上几乎没有CPU端的状态记录,因此可以做到完美的多线程渲染模式,但是这就要求我们用最高的性能去自己追踪管线的状态,譬如资源的读写状态,各种Pass,RenderTarget的状态,这些其实就和图形学没什么关系了,就回到数据结构和多线程开发等传统的计算机科学领域了,而恰恰是这个部分可能需要进行反复的推敲
所以一直到现在我都有这样的习惯:接到需求不直接往渲染器里写,而是先在Unity里快速实现验证一下,搞清思路,搞清哪些地方是可以预见的可以针对优化的性能短板,然后再在渲染器中实现完整版,因为我非常明白,API只不过是一个夹在图形开发者和硬件厂商之间的搬砖工,它只需要安静的完成自己搬砖的职责就可以了,其他的无论是管线封装也好,图形实现也罢,大多数也都是和API没什么关系的,纠结于API的学习收益并不会很大。
原作者:SaeruHikari
作者:SaeruHikari
链接:https://www.zhihu.com/question/424430509/answer/1631031617
vk是现存所有图形api中最现代,包袱最轻,概念最清晰,也是细枝末节最多的api。
换一种说法是,vk暴露给你的gpu是最gpu的,先学ogl还真不一定更好学。。。
如果对渲染不熟悉,对各种渲染管线的资源状态感到困惑,最好先搁置渲染管线。把gpu当成纯粹的异步硬件。
可以:
- 创建一个计算管线;
- 搞清楚计算管线访问buffer前中后,该buffer的状态;
- 创建更多计算管线,使用各种信号量在它们和cpu之间同步;
这样一套下来,你至少会熟悉vk的套路,如果比较灵性的话可能已经参悟gpu编程是怎么回事了。
之后:
- 了解现代gpu的渲染管线,先看整个流水线,再看各个shader stage;
- 抄一个渲染demo,带纹理的三角形就行。着重研究一下渲染管线引入的各种资源和派生状态;
- 用信号量控制计算管线和渲染管线,做些预计算/后处理,感受一下发生什么事了。
到了这里如果脑子还清醒,就说明你已经会了。再剩下的就是打开各种扩展尝试新技术了。
原作者:露米 Lumi
作者:露米 Lumi
链接:https://www.zhihu.com/question/424430509/answer/1630999744
刚好最近在做Vulkan相关的工作。我觉得,Vulkan可能难点还是在集成到引擎中遇到的一些实际设计、RenderState Cache, Descriptor Cache等问题。
至于,基础入门的话,确实API繁杂一些,但是基本数据结构和流程跟OpenGL 4.x的是差不多的。如果,题主看过DX12 或者 Metal等新一代的图形API,再去看Vulkan, 应该会觉得都差不多,就换个API的皮而已。
Vulkan是一个学院派设计的API,我刚学的时候也觉得很蛋疼,容易在细节中丢失方向。
不如,你先去看看Metal的,Apple官方的Metal的例子。然后,再去看Vulkan,你估计就发现差不多了。除了 Descriptor Set方面,比Metal更加自由之外。
或者,仔细画个思维导图,如何绘制一帧。我总结下来主要是以下几种:资源创建,Shader创建,资源和Shader绑定,Pipeline初始化,Swapchain初始化,录制Commands(录制多个Pass),提交Commands,交换SwapChain的Buffer 这个流程。
最后,Vulkan相比OpenGL优势,我觉得主要在于以下几个方面:
\1. Commands那边其实可以并行提交,可以新建多个Commands Buffer。
\2. Shader的绑定非常自由,使得可以在资源绑定方面做一些优化。
\3. PSO方面,也是自由控制的,可以更加自由地做一些优化。(我觉得DX的那种更简单直观)
参考资料有:
- Introduction - Vulkan Tutorial (入门)
- [Tips and Tricks: Vulkan Dos and Don’ts | NVIDIA Developer Blog]
- (https://link.zhihu.com/?target=https%3A//developer.nvidia.com/blog/vulkan-dos-donts/) KhronosGroup/Vulkan-Samples (这里面有些有文档描述优化思想)
- GameDev - Build | Samsung Developers (Fortnite手游的Vulkan优化的作者写的)
- Vulkan: Descriptor Sets Management · Our Machinery
- https://www.khronos.org/assets/uploads/developers/library/2019-gdc/Vulkan-Bringing-Fortnite-to-Mobile-Samsung-GDC-Mar19.pdf (GDC 2019 Fortnite演讲)
- https://renderdoc.org/vulkan-in

